CREOLA: A Revolutionary Clinician-In-the-Loop Framework for Safer AI in Healthcare
AI for every doctor
At TORTUS, our mission is to make medicine safer, smarter and kinder by giving every clinician a personal AI assistant. We are building TORTUS, an AI agent for healthcare that can take over all computer tasks from a clinician such as documentation, coding, requesting tests, and scheduling appointments.
The emergence of Generative AI, particularly through the development of Large Language Models (LLMs), unlocks great potential toward attaining this goal.

Figure 1: TORTUS will augment clinical work in a variety of tasks such as automating note-taking, handling medical coding, executing orders, and scheduling appointments
AI safety in clinical settings
Due to the rapid development and complexity of LLMs, there arises a growing need to establish a standardised evaluation framework to assess their safety and effectiveness. This issue is particularly critical within clinical environments, where ensuring patient safety stands as the foremost concern. In such settings, nuances that might be tolerable in more general applications — such as variations in wording or minor inaccuracies in creative expressions — can introduce significant risks on the diagnosis, treatment and management of a patient. This highlights the urgent requirement for tailored frameworks designed to evaluate these technologies within the clinical domain.

Figure 2: Although in everyday language those two meanings would be similar enough to not raise concern, it would be an error from a clinical standpoint as it could introduce significant risk down the line.
Introducing CREOLA: our clinician-in-the-loop framework
To ensure patient safety, TORTUS established a robust framework for the thorough and continuous evaluation of LLM models prior to their deployment within TORTUS. At the heart of our framework lies the invaluable concept of ‘clinician-in-the-loop’. Given their expertise, clinicians are uniquely positioned to identify clinical errors made by the models, making their involvement essential.
To systematically gather crucial insights in a quantitative manner, we developed the CREOLA platform. CREOLA, short for Clinical Review Of LLMs and AI, pays tribute to Creola Katherine Johnson, a pioneering human computer at NASA. Just as human computers were integral to the safe landing of Apollo moon missions, clinicians play a vital role in safely integrating AI technologies into clinical practice. Through continuous evaluation and rigorous testing, CREOLA leverages clinicians' expertise to ensure the safety and effectiveness of our AI technologies.
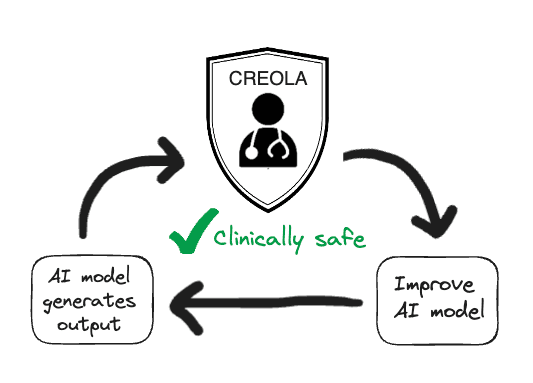
Figure 3: The CREOLA clinician-in-the-loop framework: each model’s output is evaluated by clinicians and the feedback is used to elevate safety to the highest standards paving the way for seamless incorporation into the clinical setting.
CREOLA for Speech-to-Text and Summarisation Models
The CREOLA platform currently allows for the evaluation of two types of models: speech-to-text conversion and summarisation.
In the speech-to-text section, clinicians review the transcription of consultations generated by our model while simultaneously listening to the recording. Their primary objective is to ensure the accuracy of the transcribed text, with a specific focus on medical terminology. Their corrections are allowing us to compile a comprehensive database of clinical terms that are currently not as well-recognised by AI models. This database serves as valuable input for enhancing our models’ performance in accurately transcribing medical content.
In the summarisation section, clinicians see the transcription of the consultation and the output that was generated from our models, i.e. a medical note or letter. An interactive user interface enables clinicians to smoothly and effectively identify two critical error types in the model’s output: instances of fabricated information (hallucinations) and cases where essential details are missed (omissions). Inspired by protocols in medical device certifications, we categorise errors as either ‘major’ or ‘minor’, where major indicates an impact on the diagnosis or the management of the patient. This classification system enables us to quantify changes in our models and prioritise issues in order to ensure safe integration of AI-generated summaries into clinics.
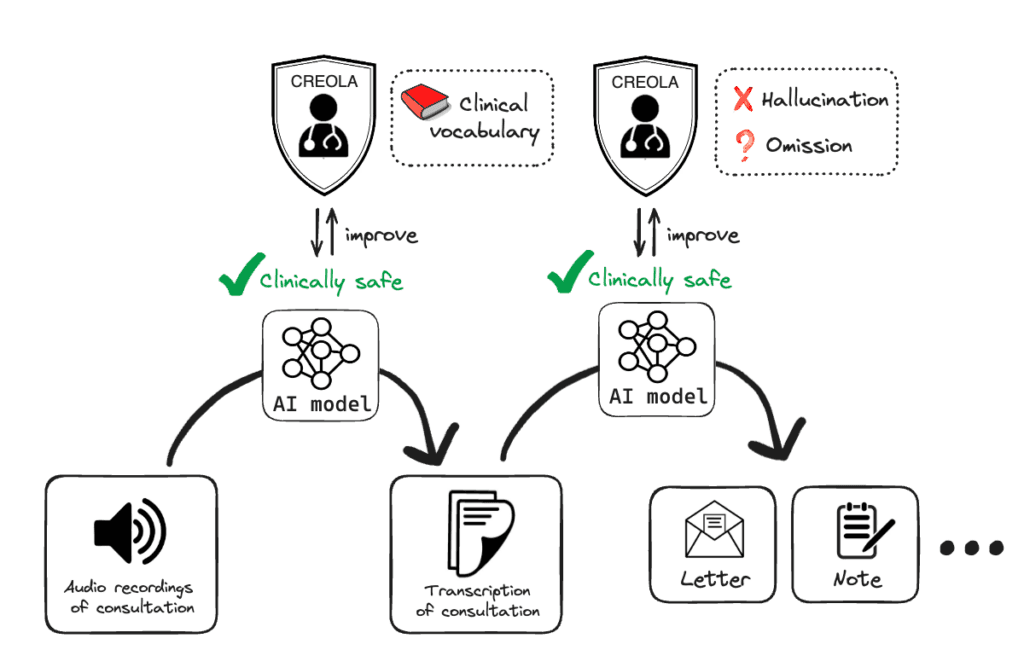
Figure 4: Overview of CREOLA for two model types: speech-to-text conversion and summarization. In the speech-to-text phase, clinicians improve the model by correcting inaccuracies in medical terminology. In the summarisation phase, clinicians improve the model by identifying instances of fabricated information (hallucinations) and where important details were missed (omissions).
Ensuring safety through continuous CREOLA evaluation
At TORTUS, we commit to meticulously evaluate every modification we make to our models, down to adjusting a few words in a prompt. For every change, we generate data that we pass through CREOLA and compare it to a decided-upon baseline dataset. Recognising the subjectivity inherent in annotation, we require annotation by at least two clinicians for each input-output pair. This step is followed by a consolidation step, i.e. a detailed review by our internal team of clinicians, ensuring a consistent evaluation of all annotations.
Following annotation and consolidation, we proceed to the analysis phase. Here, we employ a range of metrics to quantify how the alterations impact the model’s output (e.g. the total number of major hallucinations, the frequency of documents exhibiting at least one major hallucination, and the average number of major hallucinations per document). These metrics are then compared to our baseline to verify if the changes align with clinically safe standards.
Only modifications that pass this rigorous evaluation are considered for integration into our product. Any change that falls short undergoes a detailed review to pinpoint deficiencies, followed by the implementation of necessary adjustments, and the initiation of a new CREOLA cycle. Through this rigorous pipeline, we are establishing a continuous evaluation of AI models to enhance patient care while prioritising and maintaining the highest safety standards.
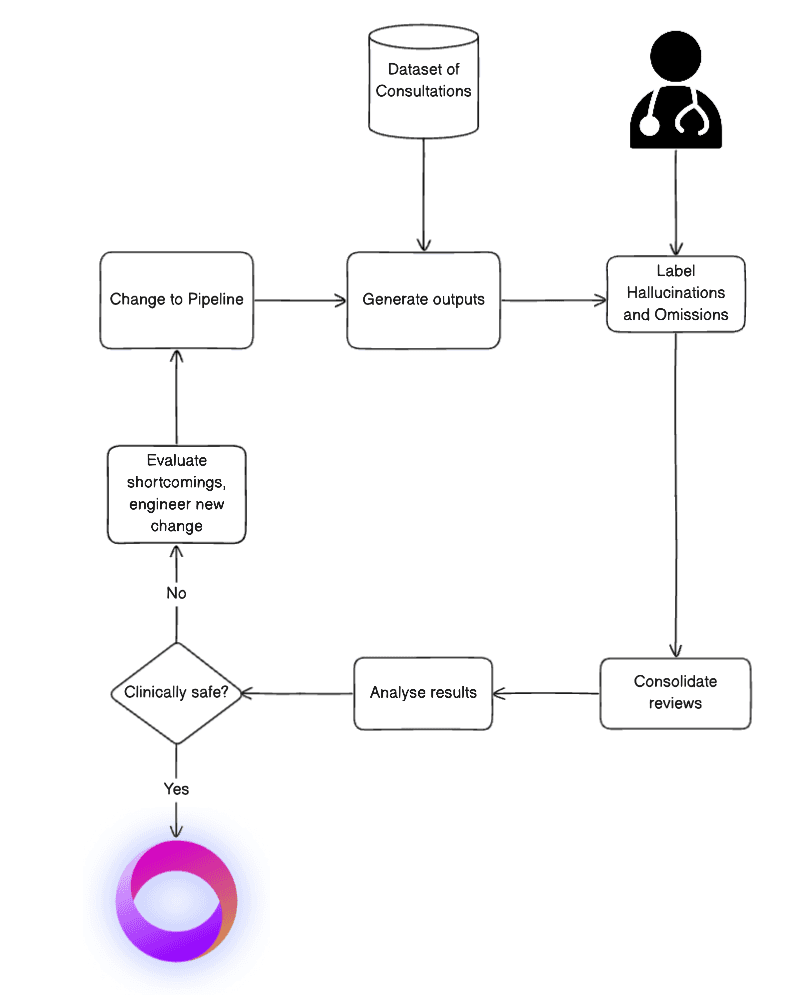
Figure 5: Ensuring safe integration through continuous CREOLA evaluation: Each modification is meticulously examined across several phases, including annotation and consolidation, to assess its safety and efficacy. Only changes that meet our strict standards are incorporated into our clinical product, ensuring the highest level of patient care.
TORTUS is committed to being net zero by 2050
TORTUS AI LTD
14487060
5 Brayford Square
E1 0SG
© TORTUS AI. All rights reserved